>>> LINK A PAGINA AGGIORNATA <<<
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
Programmare a stati significa strutturare il programma in un certo modo per: portare avanti N processi in parallelo in tempo reale (multitasking), scomporre una logica complessa in piccoli processi semplici che collaborano, aggiungere nuove funzionalità senza interferire con quelle già esistenti.
La programmazione a stati è particolarmente utile (se non indispensabile) nei sistemi dotati di poca memoria (microcontroller, PIC, Arduino ecc) e privi di un vero sistema operativo in grado di creare thread/sottoprocessi.
Il termine “programmazione a stati finiti” forse è un po’ improprio, e a volte incute un certo “timore” facendo pensare a chissà che cosa. Ci sono sistemi a stati, e ci sono formalismi matematici che descrivono in generale le macchine (o automi) a stati finiti (FSM) e le loro proprietà (di cui i sistemi reali sono specifiche implementazioni).
Esempi di sistemi a stati reali
- Cancello automatico
- Ascensore
- Sbarra parcheggio automatica
- Distributore bibite
- Semaforo
…e molti molti altri…
Un sistema a stati è qualsiasi cosa (sia hardware che software) che in ogni momento del suo funzionamento si trova in uno stato preciso tra un insieme di possibili stati. Ogni stato rappresenta “la situazione attuale”. Ad esempio un cancello automatico si può trovare sicuramente in almeno una di queste situazioni: “chiuso”, “in apertura”, “aperto”, “in chiusura”.
In ogni stato il sistema può reagire con specifiche azioni al verificarsi di determinati eventi. Per un cancello alcuni eventi possono essere: “pressione pulsante apertura”, “raggiunto fine corsa in apertura”, “urtato ostacolo”, “fotocellula oscurata”, “tempo scaduto” ecc.
Le azioni in risposta agli eventi rappresentano il comportamento del sistema, ad esempio: “avvia motore”, “accendi lampeggiante” ecc. In seguito ad un evento si può anche cambiare di stato: appena un cancello termina di aprirsi passa dallo stato “in apertura” allo stato “aperto”.
Dal punto di vista tecnico l’informazione sullo stato è semplicemente un valore (del tutto convenzionale) contenuto in una memoria (di qualsiasi tipo) che rappresenta la conoscenza che il sistema ha della situazione attuale. Con le informazioni di stato memorizzate, combinate con le letture degli ingressi, un sistema può comportarsi in modo “intelligente” di fronte ad una serie di eventi che avvengono con un certo ordine temporale. Quindi un distributore di bibite fornirà il prodotto solo dopo una sequenza ben precisa di operazioni, oppure una luce verrà accesa solo alla ricezione di una precisa sequenza di byte da una porta seriale.
In pratica ogni “macchina” in grado di interagire con il mondo reale, che riconosca o produca sequenze di eventi ordinate nel tempo in base a una memoria interna, è un sistema a stati (il sistema a stati più complesso esistente è sicuramente il nostro cervello).
Riassumendo:
- Uno stato è una situazione in cui il sistema si può trovare.
- Una macchina a stati (circuito o processo software) in ogni momento si trova in uno dei suoi stati possibili (le situazioni conosciute dalla macchina).
- In ogni stato la macchina deve riconoscere specifici eventi.
- Ad ogni evento la macchina può reagire con determinate operazioni, tra cui eventualmente cambiare stato.
Struttura generale di un programma
Dal punto di vista generale, un programma a stati si può pensare composto nel seguente modo:

Progettare un processo (lavoro, task, macchina, automa) a stati significa rispondere ai seguenti punti ancora prima di mettersi a scrivere del codice:
- In quali situazioni (e sotto situazioni) si può trovare il processo?
- A quali eventi deve reagire in ogni situazione?
- Quali operazioni deve compiere ad ogni evento?
- A quale stato deve eventualmente passare in seguito ad un evento?
La codifica è molto più semplice di quello che si può pensare. La funzione loop può richiamare ciclicamente i vari processi, anche centinaia o migliaia di volte al secondo, in modo da dare la sensazione che vengano eseguiti in parallelo contemporaneamente:
void loop()
{
processo1();
processo2();
processo3();
}
Ogni processo può essere descritto con uno switch controllato da una propria variabile di stato. Questa variabile deve mantenere il valore tra una chiamata e l’altra della funzione, perciò o si dichiara globale fuori da ogni funzione (ma per ogni processo la variabile dovrebbe avere un nome diverso), o si dichiara static all’interno della funzione (che è la scelta migliore, perché ogni processo ha la sua variabile “personale” di nome ‘stato’). Ovviamente la variabile va inizializzata allo stato che si vuole sia attivo all’avvio.
void processo1()
{
static byte stato = 0;
switch(stato)
{
case 0:
break;
case 1:
break;
case 2:
break;
default:
break;
}
}
A questo punto all’interno di ogni case basta scrivere il frammento di codice da eseguire nello stato corrispondente, che deve solo:
- Controllare se si verifica una certa condizione (evento).
- Nel caso eseguire qualche operazione.
- Eventualmente cambiare la variabile di stato.
L’ esecuzione è quindi velocissima. Ad ogni “giro di loop” per ogni processo viene eseguito solo lo stato attivo. Lo stato si limita a verificare se qualche condizione risulta vera, con una logica:
rilevazione evento → azione → cambio stato
Per chi ha scritto solo programmi “convenzionali” monotask, composti da sequenze di istruzioni da eseguire dall’inizio alla fine in un colpo solo (magari contenenti ritardi prodotti con la funzione ‘delay’), probabilmente la parte più difficile da comprendere è proprio come può essere portata avanti un’elaborazione (anche molto lenta) scomposta in più passaggi ciclici singolarmente molto veloci e senza ritardi di alcun genere.
La cosa fondamentale da focalizzare, è che in un programma con questa struttura il loop principale deve sempre chiamare tutti i processi molto velocemente, e ogni ritardo o attesa in un processo è creato permanendo in un certo stato per un certo numero di cicli (e non fermando tutta l’elaborazione per quel tempo come farebbe delay).
Per tenere conto del trascorrere del tempo, o realizzare qualche temporizzazione, in ordine di precisione crescente si può usare:
- Un piccolo delay nel loop principale per rallentarlo ad una frequenza nota in modo da poterne contare “i passaggi”. È un sistema davvero grossolano e l’errore commesso sul tempo non è controllabile, sicuramente molti secondi al minuto.
- La funzione millis per leggere il contatore di millisecondi interno (o la equivalente micros per i microsecondi), che se usata bene permette di contenere l’ errore a qualche secondo all’ora.
- Un modulo orologio RTC esterno, che permette di contenere l’errore a pochi secondi al mese. Questa è l’unica soluzione sensata per gestire tempi lunghi.
Si può anche usare una frequenza esterna di riferimento letta tramite un ingresso.
Un esempio completo
Si vuole usare un interruttore on/off per comandare due LED con sequenza 10-11-01-11 (dove 1=LED acceso). L’interruttore deve accendere, spegnere, e cambiare sequenza a fronte di una rapida apertura/chiusura non superiore a mezzo secondo. Quando almeno uno dei due LED è acceso, un terzo LED deve lampeggiare costantemente 50ms on / 1950ms off. Dopo mezz’ora dall’accensione o dall’ultimo cambio di sequenza, il sistema si deve portare in standby spegnendo tutti i LED. A questo punto per riaccendere bisogna aprire e richiudere l’interruttore.
Abbiamo quindi un ingresso (chiamiamolo INGR) a cui va applicato un adeguato debounce hardware o software. I contatti meccanici infatti ad ogni commutazione generano dei rimbalzi, cioè veloci chiusure e aperture per diversi millisecondi, che se non vengono filtrate possono essere lette come aperture e chiusure indesiderate.
Le uscite le possiamo chiamare LE1, LE2 e LAMP. L’ultima è quella a cui collegare il LED di segnalazione che blinka per 50ms ogni due secondi, e indica che almeno uno degli altri LED è acceso.
Complessivamente le funzionalità del sistema si possono scomporre in almeno tre processi indipendenti che devono essere portati avanti tutti assieme. Ogni processo compie un lavoro ben specifico e distinto da quello degli altri:
- Leggi ingresso: si occupa di leggere l’ingresso, applicare il debounce, riconoscere gli istanti di pressione e rilascio.
- Logica: si occupa di gestire la sequenza di attivazione delle uscite.
- Blink: fa lampeggiare un LED in base a un segnale di abilitazione generato da ‘logica’.
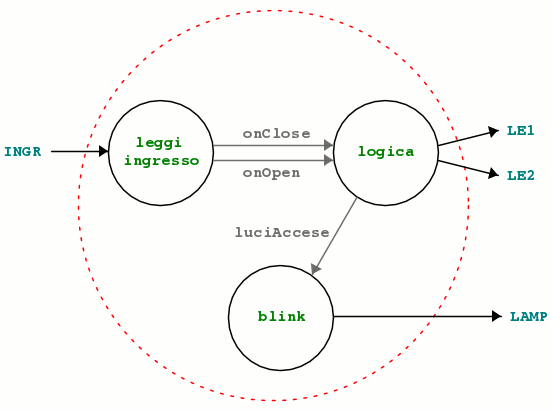
Ogni processo ha segnali in ingresso e in uscita. Possono essere segnali hardware (come le porte di ingresso/uscita), o interprocesso. Ci sono tre tipi di segnali interprocesso semplici da implementare:
- Impulso: durano un solo ciclo di programma, indicano il verificarsi di un evento in quel momento preciso, ‘onClose’ e ‘onOpen’ sono segnali impulsivi e indicano il momento esatto in cui l’interruttore viene chiuso o aperto.
- Livello: indicano costantemente la presenza o assenza di qualcosa, ‘luciAccese’ è un segnale di tipo livello.
- Messaggio: un processo scrive un’informazione (lunga a piacere) e attende conferma ricezione (ad esempio settando un flag), un altro la legge (e conferma resettando il flag). In questo esempio non si usano i messaggi.
Lo sketch
Prima di tutto definiamo dei “nomi di comodo” da usare nel resto del programma, in modo da non cospargerlo di “numeri magici” (che è facile dimenticare a cosa servono) e di livelli hardware HIGH/LOW (che sono difficili da interpretare senza lo schema elettrico sotto mano). Con le seguenti definizioni in pratica si indica già tutto quello che riguarda i collegamenti hardware (pin usati, collegamenti pull-up o pull-down, livelli letti ecc), nel resto del programma non ci si occupa mai più di loro:
#define INGR .... <--pin Arduino per ingressi e uscite
#define LE1 ....
#define LE2 ....
#define LAMP ....
#define CHIUSO .... <--livello a interruttore chiuso
#define APERTO !CHIUSO
#define SPENTO .... <--livello LED spenti
#define ACCESO !SPENTO
Poi ci servono delle variabili globali per “trasportare” i segnali interprocesso (ricordarsi sempre di inizializzare tutte le variabili che servono per una partenza corretta del sistema all’accensione), e bisogna effettuare il settaggio iniziale di ingressi e uscite (anche qui scrivere subito sulle uscite i valori “di riposo” che si vogliono avere all’avvio):
boolean onClose; //true un ciclo quando interruttore chiude
boolean onOpen; //true un ciclo quando interruttore apre
boolean luciAccese = false; //true se luci accese
//----------------------------------------------------------
void setup()
{
pinMode(INGR, INPUT);
pinMode(LE1, OUTPUT);
digitalWrite(LE1, SPENTO);
pinMode(LE2, OUTPUT);
digitalWrite(LE2, SPENTO);
pinMode(LAMP, OUTPUT);
digitalWrite(LAMP, SPENTO);
}
La funzione loop richiama semplicemente i processi:
void loop()
{
leggiIngresso();
logica();
blink();
}
Processo leggi ingresso
Questo processo deve controllare se l’ingresso ‘INGR’ varia rispetto al ciclo precedente, verificare se la variazione rimane stabile per almeno 50 millisecondi, e in tal caso impostare a true il segnale ‘onClose’ oppure ‘onOpen’ a seconda che la variazione sia una chiusura o un’apertura dell’interruttore.
Si usa una variabile ‘inPrec’ per contenere l’ultimo livello stabile rilevato (che all’avvio viene impostata uguale alla lettura attuale dell’ingresso).
Sono sufficienti due stati, uno di attesa di una variazione, e uno di “conteggio”, che controlla se durante 50ms il livello letto ritorna uguale all’ultimo livello stabile, in tal caso si ritorna in attesa senza effettuare altre azioni.
In questo modo ogni variazione di durata inferiore ai 50ms (come possono essere quelle generate dai rimbalzi) viene filtrata, e i segnali ‘onClose’ e ‘onOpen’ vengono generati solo in presenza di una commutazione reale e stabile.
I segnali ‘onClose’ e ‘onOpen’ vengono sempre “azzerati” prima di processare gli stati che possono generarli, questo garantisce che la loro durata sia di un solo ciclo di programma.
Il seguente diagramma è uno dei vari modi per rappresentare un processo a stati. Riporta gli stati (cerchi verdi), gli eventi che causano le transizioni (in blu), e un riassunto delle azioni che vengono eseguite al verificarsi degli eventi (in rosso).

void leggiIngresso()
{
static uint16_t t = millis();
static byte stato = 0;
static byte inPrec = digitalRead(INGR);
byte in = digitalRead(INGR);
onClose = false;
onOpen = false;
switch(stato)
{
case 0: //attendi
if (in != inPrec)
{
t = millis();
stato = 1;
}
break;
case 1: //timer
if (in == inPrec){
stato = 0;
}else if ((uint16_t)millis()-t >= 50){
stato = 0;
inPrec = in;
if (CHIUSO == in) { onClose = true; }
else { onOpen = true; }
}else{
// nothing
}
break;
default:
// nothing
break;
}
}
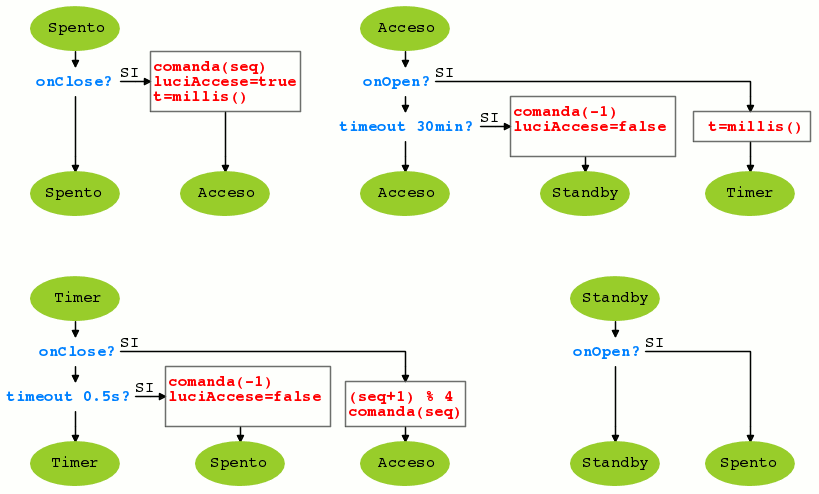
Processo logica
Il processo di controllo principale deve avere almeno quattro diversi stati: “spento”, “acceso”, “timer” (per riconoscimento comando di cambio sequenza) e “standby”. Viene comandato dai segnali prodotti da ‘letturaIngresso”, genera il segnale ‘luciAccese’ per comandare il lampeggiatore (processo ‘blink’) e comanda le uscite LE1 e LE2 con l’aiuto di una piccola funzione esterna chiamata appunto ‘comanda’.
La funzione ‘comanda’ riceve un argomento, i valori da da 0 a 3 indicano come devono essere accesi i LED, mentre il valore -1 significa tutto spento.
Il processo ha una variabile interna ‘seq’ che contiene il valore da passare a ‘comanda’. Questa variabile viene letta quando si passa dallo stato ‘spento’ ad ‘acceso’, e viene incrementata ogni volta che viene riconosciuta la sequenza di cambio (breve apertura e richiusura dell’interruttore). L’incremento viene effettuato contando in modulo quattro, per cui i valori assunti dalla variabile variano circolarmente da 0 a 3.
Quando l’interruttore viene aperto (segnale ‘onOpen’ true) si transita nello stato ‘timer’. Se l’interruttore rimane aperto oltre mezzo secondo viene considerato spegnimento e si ritorna allo stato ‘spento’.
Infine nello stato acceso si controlla se dall’ultimo salvataggio del valore di millis() sono trascorsi trenta minuti (1800000ms), in tal caso le luci si spengono e si passa allo stato standby, da cui si esce solo aprendo l’interruttore.
Il processo genera anche il segnale ‘luciAccese’ di tipo livello, che permane a true durante tutto il tempo in cui almeno un LED è acceso.
Il seguente diagramma, più simile a un flowchart, è un secondo modo per rappresentare un processo a stati. Anche qui in ogni stato sono evidenziate le condizioni e le azioni intraprese quando le condizioni risultano vere. Le frecce finali indicano per ogni singolo caso lo stato raggiunto.
void comanda(char n)
{
if (-1 == n){
digitalWrite(LE1, SPENTO);
digitalWrite(LE2, SPENTO);
}else if (0 == n){
digitalWrite(LE1, ACCESO);
digitalWrite(LE2, SPENTO);
}else if ((1 == n) || (3 == n)){
digitalWrite(LE1, ACCESO);
digitalWrite(LE2, ACCESO);
}else if (2 == n){
digitalWrite(LE1, SPENTO);
digitalWrite(LE2, ACCESO);
}else{
// nothing
}
}
//----------------------------------------------------------
void logica()
{
static byte stato = 0;
static uint32_t t;
static byte seq = 0;
switch(stato)
{
case 0: //spento
if (onClose)
{
comanda(seq);
luciAccese = true;
t = millis();
stato = 1;
}
break;
case 1: //acceso
if (onOpen){
t = millis();
stato = 2;
}else if (millis()-t > 1800000L){
comanda(-1);
luciAccese = false;
stato = 3;
}else{
// nothing
}
break;
case 2: //attesa 500ms
if (onClose){
seq = (seq + 1) % 4;
comanda(seq);
stato = 1;
}else if (millis()-t >= 500){
comanda(-1);
luciAccese = false;
stato = 0;
}else{
// nothing
}
break;
case 3: //standby
if (onOpen) { stato = 0; }
break;
default:
// nothing
break;
}
}
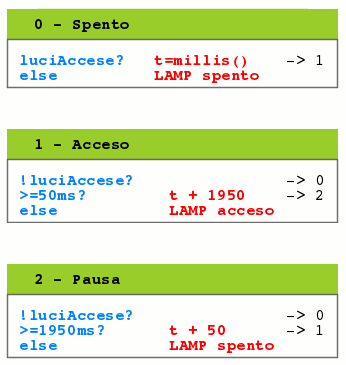
Processo blink
Il processo ‘blink’ si occupa esclusivamente di far lampeggiare in modo assimmetrico (con basso duty cycle) il LED collegato all’uscita ‘LAMP’. Il lampeggio è controllato dal segnale livello ‘luciAccese’. Quando questo segnale è true il lampeggio è attivo.
Aver strutturato l’intero programma in tre processi indipendenti e cooperanti permette di mantenere semplici i singoli processi. Ciascuno si occupa solo di quello che lo riguarda, sgravando tutti gli altri da dettagli inutili alla loro funzione.
A ‘blink’ non interessa nulla di sapere se l’interruttore sta rimbalzando, mentre a ‘leggiIngresso’ non interessa nulla sapere se il LED LAMP è nella fase acceso o spento. Sono compiti totalmente diversi. Riuscire a individuare questi compiti in un sistema permette di decomporlo nei processi corretti semplificando molto la programmazione.
Il disegno seguente è un terzo metodo per rappresentare gli stati di un processo:
void blink()
{
static byte stato = 0;
static uint16_t t;
switch(stato)
{
case 0: //spento
if (luciAccese){
t = millis();
stato = 1;
}else{
digitalWrite(LAMP, SPENTO);
}
break;
case 1: //acceso
if (!luciAccese){
stato = 0;
}else if ((uint16_t)millis()-t >= 50){
t += 1950;
stato = 2;
}else{
digitalWrite(LAMP, ACCESO);
}
break;
case 2: //pausa
if (!luciAccese){
stato = 0;
}else if ((uint16_t)millis()-t >= 1950){
t += 50;
stato = 1;
}else{
digitalWrite(LAMP, SPENTO);
}
break;
default:
// nothing
break;
}
}
Riassumendo
Quando si programma un sistema strutturato a stati, quello che si fa normalmente è questo:
- Si leggono gli ingressi (applicando un opportuno anti rimbalzo hard/soft se sono ingressi sporchi come i contatti meccanici).
- In base alla situazione attuale (stato) e ai valori letti, si decide quali operazioni svolgere (compreso il comando delle uscite e l’ eventuale aggiornamento della situazione attuale).
- La situazione attuale (stato) si mantiene in apposite variabili usate per quello scopo (che vanno all’inizio impostate in modo da permettere una partenza regolare all’accensione o ad un reset).
Detto questo sono da decidere:
- In quali situazioni (e sotto situazioni) si può trovare il sistema.
- A quali eventi deve reagire in ogni situazione.
- Quali operazioni deve compiere ad ogni reazione (compreso un eventuale cambio di stato).
Tutto questo si fa con strutture if/else oppure switch, e variabili usate opportunamente (come indicatori di stato, contatori, flag ecc)
Il funzionamento/avanzamento del sistema è formato dalla continua rapida ripetizione di tutti questi punti.
Se oltre a questo c’è anche da tenere conto del trascorrere del tempo (o si devono realizzare temporizzazioni), in ordine di precisione crescente si possono usare:
- Piccoli delay nel loop principale per rallentarlo ad una frequenza nota (in modo da poterne contare “i passaggi”.
- La funzione millis per leggere il contatore di millisecondi interno.
- Un modulo orologio RTC esterno.
Post forum Arduino da cui è nato questo articolo
- Aiuto, sostituire delay con millis
- millis()….maledetto millis() (parte 1)
- millis()….maledetto millis() (parte 2)
- uso millis()
- realizzazione di un ascensore a 3 piani
- Progetto Serra Automatica
- Lettura byte da seriale
- Pulsante con ritardo attivazione usando millis
Progetti reali con programmazione a stati
- L’ orologio di cartone (Arduino)
- Ricevitore DCF77 (PIC)
(26/8/2018)