Un tormentone frequente nella programmazione di operazioni tramite Arduino è quello di fare più cose contemporaneamente. Ad esempio far lampeggiare un LED mentre si esegue un altro compito. O continuare a leggere gli ingressi e reagire ad eventi anche durante le fasi di attesa.
In effetti, compatibilmente con le risorse disponibili (memoria, numero di ingressi o uscite), si può pensare di far eseguire ad Arduino molti compiti contemporaneamente, anche indipendenti tra loro.
Prendiamo ad esempio questo processo schematico da eseguire continuamente nella funzione loop:
...a... ...b... delay(5000); ...c... ...d... delay(10000);
Vogliamo eseguire le operazioni ‘a’ e ‘b’ (non ci interessa qui sapere cosa siano), fare una pausa di cinque secondi, eseguire le operazioni ‘c’ e ‘d’, fare una pausa di dieci secondi, e ricominciare subito da capo.
Sicuramente scrivendo queste sei istruzioni nella funzione loop raggiungiamo lo scopo. Ma poi ci viene anche in mente di far lampeggiare regolarmente un LED, mezzo secondo acceso e mezzo secondo spento:
digitalWrite(PIN_LED, LIVELLO_ACCESO); delay(500); digitalWrite(PIN_LED, LIVELLO_SPENTO); delay(500);
E qui iniziano subito i problemi… è evidente che se scriviamo le istruzioni per il lampeggio del LED di seguito a quelle del primo processo, verranno eseguite solo quando sono state eseguite tutte quelle del primo processo, e quindi il lampeggio risulta bloccato ad ogni giro per 15 secondi.
Allo stesso modo anche i tempi del primo processo risultano alterati, perché tra la sua fine e la riesecuzione dell’operazione ‘a’ passa un secondo, portato via dall’esecuzione del processo di lampeggio.
Se a questo punto ci serve eseguire anche un terzo processo come schematizzato di seguito, non solo continuiamo a non rispettare i tempi, ma peggioriamo ancora la situazione, perché l’intera esecuzione delle istruzioni contenute nella funzione loop dura almeno quanto la somma di tutti i delay, cioè 77,5 secondi!
...g... delay(60000); ...h... delay(500); ...i... delay(1000);
Questa interferenza tra i tempi dei vari processi è esattamente ciò che si vuole evitare, in modo che ogni processo vada avanti in parallelo agli altri indipendentemente.
Ciò si realizza con due passi fondamentali: il primo è quello di non usare la funzione bloccante delay (che congela completamente l’esecuzione per il tempo stabilito), il secondo è quello di scrivere l’ordine di esecuzione delle operazioni in forma non bloccante.
Eliminare delay
Il primo passo consiste nel contare il trascorrere del tempo con la funzione millis. Questa funzione legge “l’ora di sistema” di Arduino espressa in millisecondi e restituisce un valore unsigned long a 32 bit.
È possibile salvarsi un’ “ora di inizio” in una variabile (di tipo unsigned long), e poi continuare a calcolare il tempo trascorso da quel momento facendo la differenza tra l’ora di sistema (che aumenta) e quella salvata. Un rimpiazzo diretto di delay con millis nel primo processo può quindi essere questo:
...a...
...b...
inizio = millis();
while (millis()-inizio < 5000) {}
...c...
...d...
inizio = millis();
while (millis()-inizio < 5000) {}
In questo modo abbiamo sostituito la funzione delay con un ciclo che svolge esattamente la stessa operazione, cioè restare li bloccato a ciclare finché non è trascorso il tempo previsto.
Quindi siamo ancora al punto di partenza, cioè un codice che si blocca in quel punto per un certo tempo esattamente come con delay.
Non bloccare
E qui arriva il secondo passo fondamentale, impossibile da realizzare con delay, ma facilmente implementabile con millis. L’idea è quella di scomporre le varie fasi in cui si viene a trovare il processo in blocchetti di istruzioni messi sotto condizione if, in modo che vengano eseguiti solo nel momento in cui la condizione è vera, e saltati in caso contrario (lasciando l’esecuzione libera di proseguire con altre operazioni).
Le condizioni di ogni blocchetto si possono poi abilitare o disabilitare usando un’apposita variabile di controllo (variabile di stato o fase), ad esempio il primo processo può essere riscritto così:
if (fase==1){
...a...;
...b...;
inizio = millis();
fase=2;
}
if (fase==2 && (millis()-inizio >= 5000)){
...c...;
...d...;
inizio = millis();
fase=3;
}
if (fase==3 && (millis()-inizio >= 10000)) fase = 1;
All’inizio ‘fase’ è impostata a 1, per cui è abilitato solo il primo blocchetto, vengono eseguite le operazioni ‘a’ e ‘b’, viene salvata “l’ora di sistema”, ma invece di bloccarsi in un ciclo di attesa si cambia la variabile di fase, disabilitando l’esecuzione del primo blocchetto e abilitando quella del secondo.
La condizione del secondo diventerà vera solo dopo cinque secondi, ma in tutto questo tempo non restiamo fermi li ad aspettare, piuttosto proseguiamo subito oltre.
Va ricordato che questi if sono valutati ripetutamente dal primo all’ultimo migliaia di volte al secondo, perché sono scritti all’interno della funzione loop che è un ciclo senza fine.
Quando dopo cinque secondi, e innumerevoli cicli di loop, la condizione diventa vera, allora, e solo in quel momento, vengono eseguite le operazioni ‘c’ e ‘d’, viene salvata la nuova “ora di sistema”, e variata di nuovo la fase.
A questo punto di nuovo per dieci secondi nessuna delle tre condizioni risulta vera, e nel frattempo il loop continua a girare senza blocchi, limitandosi a testare in continuazione le condizioni.
Allo scadere dei dieci secondi anche la terza condizione diventa vera, e la fase viene impostata per abilitare di nuovo il primo if.
Risultato: il processo, inteso come ordine di esecuzione delle operazioni e pause tra di esse, è invariato, ma non vi è alcun rallentamento/blocco nell’esecuzione.
Quindi: scrivendo anche gli altri processi in questo modo (ciascuno con una sua personale variabile di fase e una sua personale variabile di tempo iniziale), si possono scrivere di fila gli if di tutti i processi, sicuri che verranno valutati tutti migliaia di volte al secondo. E questo significa che tutti i processi funzioneranno virtualmente in parallelo, il LED del secondo processo lampeggerà regolarmente, mentre magari gli altri due processi sono nelle fasi di attesa di dieci o sessanta secondi.
Tutto qua?
Fondamentalmente si, questo è il principio base: tanti if da valutare, operazioni da eseguire solo nel momento in cui qualcuno di essi risulta vero, e variabili di controllo per abilitare/disabilitare e memorizzare i tempi.
Per individuare le fasi in cui decomporre un processo sotto forma di condizioni (di cui una e una sola alla volta deve essere abilitata), è sufficiente osservare dove il processo deve rimanere in attesa di qualcosa (eventi, timeout ecc). Ogni situazione di attesa è una ben precisa fase, e poi possono eventualmente esserci fasi “accessorie” come una di inizializzazione.
Fermi restando i principi descritti, poi le implementazioni possono variare, ad esempio tutti gli if di un singolo processo possono essere meglio raggruppati in un’unica struttura if/else if/else if, o in una equivalente struttura decisionale switch. Ad esempio il primo processo lo possiamo riscrivere così:
switch (fase)
{
case 1:
...a...;
...b...;
inizio = millis();
fase=2;
break;
case 2:
if (millis()-inizio >= 5000){
...c...;
...d...;
inizio = millis();
fase=3;
}
break;
case 3:
if (millis()-inizio >= 10000) fase = 1;
break;
}
E le funzioni?
Spesso la domanda è: “come faccio compiere delle operazioni (ad esempio il solito lampeggio LED) mentre sto eseguendo una funzione che dura un certo tempo?”
La risposta è: si deve scrivere anche la funzione in modo non bloccante, in modo che la sua esecuzione avvenga non in una sola chiamata, ma in un’infinità di continue chiamate singolarmente brevissime.
Spesso in qualche punto del programma si trova ciclo while/for che compie diverse operazioni, magari con dei delay che complessivamente fanno si che il suo tempo di esecuzione sia considerevole (non compatibile con un loop libero di girare alla massima velocità).
In questo caso la soluzione è eliminare anche i for/while contenenti attese, trasformandoli in stati/fasi da testare continuamente.
Ad esempio in un punto del programma potrebbe esserci un ciclo come il seguente, con cento iterazioni e cento pause da un secondo, e quindi un tempo di esecuzione di cento secondi!
for (i=0; i<100; i++)
{
...x...
delay(1000);
}
Il diagramma di flusso che rappresenta il for è questo:
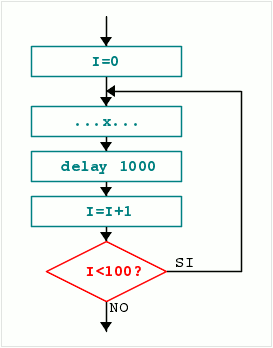
Per decomporlo ci serve una fase di inizializzazione per la variabile ‘I’, una fase in cui viene eseguita l’operazione ‘x’ e salvato il tempo di inizio attesa, e una fase di attesa di un secondo, alla fine della quale si incrementa la variabile di ciclo e si testa se si deve rieseguire l’operazione ‘x’ o se le iterazioni sono finite:
if (fase==1) { i=0; fase=2; }
if (fase==2) { ...x...; inizio=millis(); fase=3; }
if (fase==3 && (millis()-inizio >= 1000)){
i++;
if (i<100) fase=2; else fase=4;
}
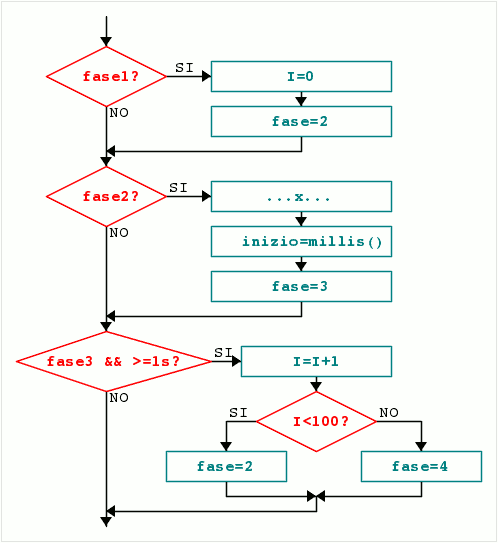
Come si vede il for, che prima bloccava tutto per cento secondi, è diventato una sequenza di tre if non bloccanti, anche se alla fine le operazioni e le pause tra esse sono rimaste le stesse.
Certo c’è la fase 4… cos’è la fase 4? Ricordiamo che strutturando il codice in modo non bloccante non si scrive più una sequenza monolitica di passi “esegui questo, poi quest’altro ecc” da eseguire dal primo all’ultimo, ma piuttosto si abilitano/disabilitano delle condizioni, per renderle più o meno eseguibili nei momenti/contesti voluti. Quindi fase 4 significa semplicemente “ciclo finito”, e sarà compito di un’altra parte del programma valutare questa informazione, ed eventualmente riavviare il ciclo riabilitando la fase 1.
Macchine a stati finiti
E con questo, senza neppure nominarle, abbiamo scritto delle “macchine a stati finiti”, termine che tanto “terrorizza” o scoraggia i meno addetti, ma che alla fine non sono niente altro che quanto detto fin qui: procedimenti suddivisi in ben precise fasi di funzionamento esplicite.