>>> LINK A PAGINA AGGIORNATA <<<
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
- .
.
.
.
I wildcard…
…chiamati anche caratteri jolly, o metacaratteri, servono per costruire delle stringhe di ricerca, ad esempio per trovare tutti i nomi di una lista che corrispondono a un certo criterio.
La stringa di ricerca, o maschera di ricerca, può contenere degli asterischi ‘*’ per indicare zero o più caratteri qualsiasi, e dei punti di domanda ‘?’ per indicare un carattere qualsiasi obbligatorio in quella posizione.
Esempi:
| Ricerca | Corrispondenza |
|---|---|
| *.jpg | Tutto quello che finisce con ‘.jpg’ |
| ??????.txt | Tutti i nomi di 6 caratteri che finiscono con ‘.txt’ |
| *zon*.??? | Tutto quello che contiene ‘zon’ e finisce con punto e 3 caratteri, ad esempio ‘eurozona.txt’ |
| vid* | Tutto quello che inizia con ‘vid’ |
| isol?.* | Tutti i nomi di cinque caratteri che iniziano con isol e proseguono con un punto e altri caratteri, ad esempio: isola.jpg isole.baleari.pdf ecc |
| ?????*h | Tutti i nomi di almeno 6 caratteri che finiscono con ‘h’ |
| * | Tutto (anche niente) |
| *.* | Tutto quello che contiene almeno un punto |
| ? | Tutti i nomi composti da un solo carattere |
| ?* | Tutto quello che ha almeno un carattere |
Alla ricerca dell’algoritmo
Siccome la gestione dei wildcard è già presente e funzionante in qualsiasi sistema operativo in grado di gestire dei file, normalmente nessuno si occupa di “reinventare la ruota”.
Ci sono però casi che prevedono di occuparsene… sistemi embedded privi di sistema operativo, esercizi scolastici, o anche solo per far girare il neurone meglio della settimana enigmistica…
Ecco quindi che da una domanda sul forum Arduino nasce una goliardica “sfida Bartezzaghi” (nonché scusa per scrivere di vari argomenti): qual è il, o almeno un, procedimento per vedere nel modo più generale possibile se una generica stringa “matcha” con una maschera jolly?
Requisiti:
- Escludiamo in partenza algoritmi ricorsivi, che esistono, ma dobbiamo usare poca memoria.
- Escludiamo anche l’uso esclusivo di linguaggi ad altissimo livello come Python, che semplificano perfino troppo, ma serve un sistema operativo funzionante.
- Anzi, per farci proprio del male, l’algoritmo deve essere implementabile non solo in C su Arduino, ma anche in assembly… (ci avanza “ciusto ciusto” un sonnecchiante Z80 sempre valido didatticamente).
- L’algoritmo deve essere generale, cioè deve accettare maschere di ricerca arbitrariamente lunghe e complesse, ad esempio: *AB.*J?*F.S**BB*GZ
- E naturalmente senza copiare, se no non vale…
Per ora lasciamo stare altre questioni come caratteri non ASCII, stringhe vuote, differenza maiuscole/minuscole ecc, e assumiamo di lavorare sempre con maschere e stringhe ASCII “well formed” di almeno un carattere.
Dopo averci pensato un po’, mi sembra che la soluzione più semplice sia un procedimento generale di questo tipo: individuo nella maschera diverse submask (i gruppi di caratteri separati dagli asterischi o confinanti con gli estremi) e le cerco nella stringa a posizioni incrementali.
 Ci sono tre casi specifici da gestire:
Ci sono tre casi specifici da gestire:
- Maschera senza asterischi iniziali: la submask iniziale va cercata esattamente (e solo) all’inizio della stringa.
- Maschera senza asterischi finali: la submask finale va cercata esattamente (e solo) alla fine della stringa.
- Maschera totalmente priva di asterischi: la submask corrisponde all’intera maschera, che deve corrispondere esattamente all’intera stringa.
Per avere qualcosa su cui lavorare possiamo pensare al seguente campo di gioco. Due stringhe: maschera ‘M’ e dati ‘S’. Due indici ‘A’ e ‘B’ per identificare inizio e fine di una submask. Un indice ‘I’ che “scorre” da ‘A’ a ‘B’. Un indice ‘C’ che identifica la posizione iniziale da cui cercare nella stringa ‘S’ (questo indice deve avanzare ad ogni submask identificata correttamente). Un indice ‘J’ per “scorrere” la stringa ‘S’. E due indici ‘maxM’ e ‘maxS’ che identificano l’ultimo carattere delle stringhe.
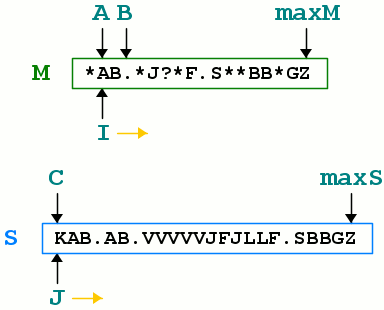
La quantità di indici può far pensare ad un procedimento molto complesso, in realtà sono proprio loro a renderlo invece semplice ed esprimibile anche a bassissimo livello (come richiede per l’implementazione in assembly).
L’algoritmo…
I seguenti diagrammi di flusso compatti rappresentano l’intera procedura generale, assumendo di lavorare con indici, e funzioni che ritornano true/false.
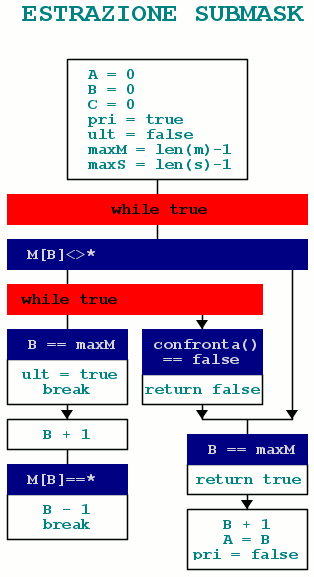
Estrarre le submask è “banale”. Si parte con i puntatori (o indici) ‘A’ e ‘B’ posizionati sul primo carattere. Se è asterisco avanzano tutti e due di una posizione. Se non è asterisco avanza solo ‘B’… fino a fine maschera o al prossimo asterisco. A questo punto ‘A’ e ‘B’ delimitano esattamente una submask. Dopo il confronto di una submask con la stringa dati, se ‘B’ è arrivato a fine maschera abbiamo finito con riconoscimento positivo, altrimenti ‘B’ avanza di una posizione e ‘A’ viene portato allo stesso punto di ‘B’, da qui si ricomincia.
I due flag ‘pri’ e ‘ult’ indicano elaborazione di submask iniziale senza asterischi, e submask finale senza asterischi. Le due condizioni possono essere contemporaneamente vere se la maschera non contiene alcun asterisco.
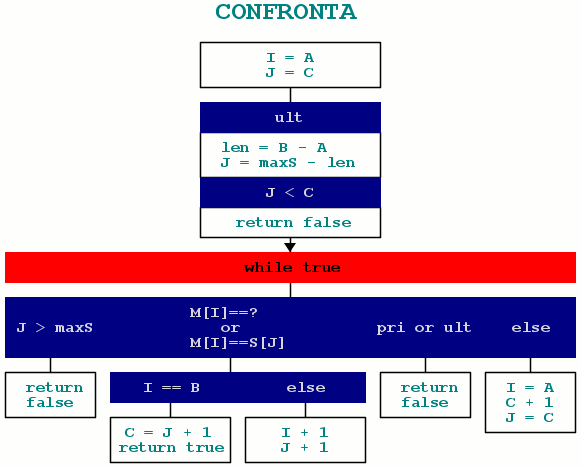
La funzione di confronto “normalmente” cerca una submask nella stringa ‘S’ a partire dall’indice ‘C’. Se tutti i caratteri della submask corrispondono si ritorna con true e con l’indice ‘C’ impostato alla prossima posizione di ricerca. Se un carattere non corrisponde, si cerca la submask una posizione più avanti (fino ad eventuale sforamento della lunghezza della stringa (J>maxS). Poi ci sono i casi particolari di primo e ultimo giro. In queste condizioni non è ammesso trovare un carattere errato. Inoltre nel caso di ultimo giro la ricerca deve essere fatta esattamente alla fine della stringa (J=maxS-len), e la submask deve essere contenuta nella sottostringa rimanente dall’indice ‘C’ in poi (a questo serve il controllo J<C).
Per verificare il funzionamento dell’intera procedura, ho scritto il seguente codice Python di test a basso livello non idiomatico, cioè senza utilizzare le specifiche possibilità del linguaggio. Le funzioni ‘verifica’ e ‘confronto’ sono l’equivalente uno a uno dei diagrammi di flusso.
#___________________________________________________________ # # Test wildcard mask - By C.Fin 2018 #___________________________________________________________ from __future__ import print_function #in Py2 #___________________________________________________________ def confronto(S, M, A, B, pri, ult, maxS): global C I = A #indice per scorrere maschera J = C #indice per scorrere stringa if ult: L = B - A J = maxS - L if J < C: return False #stringa troppo corta while True: if J > maxS: return False elif M[I] == '?' or M[I] == S[J]: if I == B: C = J + 1 #indice prossima ricerca return True #substring trovata else: I += 1 J += 1 elif pri or ult: return False #carattere diverso else: I = A #riparti da inizio submask C += 1 #nuovo inizio substring J = C #riparti da inizio substring #___________________________________________________________ def verifica(S, M): global C A = 0 #indice inizio submask B = 0 #indice fine submask C = 0 #indice inizio substring pri = True #primo giro ult = False #ultimo giro maxM = len(M) - 1 #ultimo indice maschera maxS = len(S) - 1 #ultimo indice stringa while True: if M[B] != '*': while True: #estrae submask (indici A B) if B == maxM: ult = True; break B += 1 if M[B] == '*': B -= 1; break #confronta submask con substring da indice C if not confronto( S, M, A, B, pri, ult, maxS): return False if B == maxM: return True B += 1 A = B pri = False #___________________________________________________________ mask = '1*AB.*??Hq**GZGZ*GZ.d' stri = '12345AB.AB.FFHF.NMHqwerLBGZGZGZ.d' print(verifica(stri, mask))
L’algoritmo sembra essere generale e fornisce i risultati corretti per un ampio insieme di coppie maschera/stringa.
Ora si tratta di rifattorizzare usando le caratteristiche specifiche o scorciatoie di ogni linguaggio. In Python ad esempio una lista di submask si può ottenere in modo immediato con un semplice split(‘*’), ed è naturale usare gli indici, le enumerazioni, le iterazioni automatiche. In C si possono usare anche i puntatori, che rendono il codice compilato più veloce ed efficiente. In assembly invece non abbiamo le variabili, ma celle di memoria (da usare come variabili), e registri del processore (che in alcuni casi possono svolgere la funzione di variabili ad alta velocità). In questo caso conviene ragionare sempre in termini di puntatori, in quanto strutturare il programma per “emulare” array e indici porterebbe ad un eccessivo appesantimento del codice.
La versione Python
#___________________________________________________________ # # Test wildcard mask - Python version - By C.Fin 2018 #___________________________________________________________ def confronto(S, C, sm, pri, ult, maxS): B = len(sm) - 1 I = 0 #indice per scorrere submask J = C #indice per scorrere stringa if ult: J = len(S) - len(sm) if J < C: return -1 #stringa troppo corta while True: if J > maxS: return -1 elif sm[I] == '?' or sm[I] == S[J]: if I == B: return J + 1 #indice prossima ricerca else: I += 1 J += 1 elif pri or ult: return -1 #carattere diverso else: I = 0 #riparti da inizio submask C += 1 #nuovo inizio substring J = C #riparti da inizio substring #___________________________________________________________ def verifica(S, M): C = 0 #indice inizio substring maxS = len(S) - 1 submasks = M.split('*') maxM = len(submasks) - 1 for n, sm in enumerate(submasks): if sm: C = confronto(S, C, sm, n==0, n==maxM, maxS) if C == -1: return False return True #___________________________________________________________
La funzione confronto non può cambiare più di tanto, fondamentalmente era importante togliere di mezzo quella variabile globale. Nelle funzioni Python le variabili non possono essere modificate “sul posto”, perciò devono essere restituite come valori di ritorno. In questa versione quindi al posto di ritornare True/False, si ritorna l’indice prossima ricerca ‘C’, oppure il valore -1 in caso di confronto fallito (l’equivalente del False della prima versione di prova).
La funzione verifica invece può essere decisamente compattata grazie alla lista ‘submasks’ ottenuta con un semplice split su asterisco della maschera. In questa funzione ‘maxM’ non identifica l’ultimo carattere della maschera, ma l’ultima submask.
Un asterisco iniziale genera una submask vuota iniziale (stessa cosa per un asterisco finale), usando l’indice ‘n’ ottenuto dalla enumerazione è immediato sapere se stiamo lavorando con la prima (n==0) o l’ultima (n==maxM) submask.
Non vengono calcolati gli indici ‘A’ e ‘B’ perché alla funzione ‘confronto’ si passa ogni volta un’intera submask, che dentro la funzione ‘confronto’ avrà indici da 0 a len(sm)-1.
La Versione Arduino
//__________________________________________________________ // // Test wildcard - Arduino version - By C.Fin 2018 //__________________________________________________________ boolean confronto(char* A, char* B, char** C, boolean pri, boolean ult, char* maxS) { char* I = A; char* J = *C; if(ult) { J = maxS - (B - A); if(J < *C) return false; } while(true) { if(J > maxS) return false; else if(*I == '?' || *I == *J) { if(I == B){ *C = J + 1; return true; } else { I++; J++; } } else if(pri || ult) return false; else{ I = A; (*C)++; J = *C; } } } //__________________________________________________________ boolean verifica(char S[], char M[]) { char* A = M; char* B = M; char* C = S; boolean pri = true; boolean ult = false; char* maxM = M + strlen(M) - 1; char* maxS = S + strlen(S) - 1; while(true) { if(*B != '*') { while(B < maxM && *(B+1) != '*') B++; if(B == maxM) ult = true; if(!confronto(A, B, &C, pri, ult, maxS)) return false; } if(B == maxM) return true; B++; A = B; pri = false; } } //__________________________________________________________ void setup() { Serial.begin(9600); delay(2000); char mask[] = "?????*h"; char stri[] = "1234hh"; Serial.println(verifica(stri, mask)); } //__________________________________________________________ void loop() { } //__________________________________________________________
La versione C per Arduino è la sagra dei puntatori. In particolare il puntatore C è un puntatore a puntatore per permettere la sua modifica “sul posto” all’interno della funzione ‘confronto’. Le funzioni ritornano true o false. L’estrazione delle submask è svolta da un semplice ciclo while a due condizioni in and.
La versione Z80
;___________________________________________________________
;
; Test wildcard - Z80 version - By C.Fin 2018
;___________________________________________________________
programma #EQU 32768 ;indirizzo programma
dati #EQU 40000 ;RAM dati
#define _pri_ 0 ;bit flag primo giro
#define _ult_ 1 ;bit flag ultimo giro
;___________________________________________________________
#ORG programma
LD HL,stri ;; addr stringa
LD DE,mask ;; addr maschera
CALL verifica
JP NZ,L010 ;; se true, A=1
LD A,1
JP L011
L010:
XOR A ;; altrimenti A=0
L011:
LD (_result_),A ;; salva risultato
RET ;; fine, ritorna al monitor
;___________________________________________________________
;
; Subroutine verifica, input: HL=addr stringa
; DE=addr maschera
; output: flag Z settato se OK
;
; Il registro D' viene usato come bit flag
;___________________________________________________________
verifica:
CALL init
loop_verifica: ;; while(true)
LD HL,(_B_) ;; if(*B != '*')
LD A,(HL)
CP '*'
JP Z,L003
CALL submask_estract
CALL confronto ;; if(!confronto()) retfalse
JP NZ,retfalse
L003:
LD HL,(_B_) ;; if(B == maxM) ret true;
LD DE,(_maxM_)
AND A
SBC HL,DE
RET Z
LD HL,(_B_) ;; B++;
INC HL
LD (_B_),HL
LD (_A_),HL ;; A = B;
EXX
RES _pri_,D ;; pri = false;
EXX
JP loop_verifica
;___________________________________________________________
init:
LD (_S_),HL
LD (_M_),DE
LD (_A_),DE ;; char* A = M;
LD (_B_),DE ;; char* B = M;
LD (_C_),HL ;; char* C = S;
EXX
SET _pri_,D ;; boolean pri = true;
RES _ult_,D ;; boolean ult = false;
EXX
LD HL,(_M_) ;;char* maxM = M + strlen(M) - 1
CALL strlen
DEC HL
LD DE,(_M_)
ADD HL,DE
LD (_maxM_),HL
LD HL,(_S_) ;;char* maxS = S + strlen(S) - 1
CALL strlen
DEC HL
LD DE,(_S_)
ADD HL,DE
LD (_maxS_),HL
RET
;___________________________________________________________
submask_estract:
LD HL,(_B_)
LD DE,(_maxM_)
submask_loop:
LD A,H ;; if(B == maxM)
CP D
JP NZ,L004
LD A,L
CP E
JP NZ,L004
LD (_B_),HL
EXX
SET _ult_,D ;; ult = true
EXX
RET ;; break
L004:
INC HL ;; B++
LD A,(HL) ;; if(*B=='*')
CP '*'
JP NZ,submask_loop
DEC HL ;; B--
LD (_B_),HL
RET ;; break
;___________________________________________________________
confronto:
LD HL,(_A_) ;; char* I = A;
LD (_I_),HL
LD HL,(_C_) ;; char* J = *C;
LD (_J_),HL
EXX
BIT _ult_,D ;; if(ult)
EXX
JP Z,confronto_loop
LD HL,(_B_) ;;J = maxS - (B - A);
LD DE,(_A_)
AND A
SBC HL,DE
EX DE,HL
LD HL,(_maxS_)
AND A
SBC HL,DE
LD (_J_),HL
LD DE,(_C_) ;; if(J < *C) retfalse;
AND A
SBC HL,DE
JP C,retfalse
confronto_loop: ;; while(true)
LD HL,(_maxS_) ;; if(J>maxS) retfalse;
LD DE,(_J_)
AND A
SBC HL,DE
JP C,retfalse
LD HL,(_I_) ;; else if(*I=='?' || *I==*J)
LD A,(HL)
CP '?'
JP Z,L050
LD HL,(_J_)
CP (HL)
JP NZ,L060
L050:
LD HL,(_I_) ;; if(I == B)
LD DE,(_B_)
AND A
SBC HL,DE
JP NZ,L055
LD HL,(_J_) ;; *C = J + 1;
INC HL
LD (_C_),HL
XOR A ;; return true;
RET
L055:
LD HL,(_I_) ;; else { I++; J++; }
INC HL
LD (_I_),HL
LD HL,(_J_)
INC HL
LD (_J_),HL
JP confronto_loop
L060:
EXX ;; else if(pri || ult) retfalse
BIT _pri_,D
EXX
JP NZ,retfalse
EXX
BIT _ult_,D
EXX
JP NZ,retfalse
LD HL,(_A_) ;; else{ I=A; (*C)++; J=*C; }
LD (_I_),HL
LD HL,(_C_)
INC HL
LD (_C_),HL
LD (_J_),HL
JP confronto_loop
;___________________________________________________________
retfalse:
XOR A
DEC A
RET
;___________________________________________________________
;
; Input: HL=addr stringa Output: HL=len stringa
;___________________________________________________________
strlen:
LD BC,0
XOR A
CPIR
LD HL,-1
AND A
SBC HL,BC
RET
;___________________________________________________________
#ORG dati
_result_ #DB 0
_A_ #DW 0
_B_ #DW 0
_C_ #DW 0
_M_ #DW 0
_S_ #DW 0
_maxM_ #DW 0
_maxS_ #DW 0
_I_ #DW 0
_J_ #DW 0
mask #DB "?????*h", 0
stri #DB "1234hh", 0
;___________________________________________________________
Per l’asm, non essendoci variabili, funzioni, valori di ritorno, occorre fare delle assunzioni iniziali basate sulla specifica CPU/MCU che si vuole usare, e sull’hardware specifico utilizzato (mappa di memoria). In questo caso specifico l’hardware di prova permette di caricare il programma a partire dall’indirizzo 32768 (come indicato nella direttiva di compilazione ORG).
I dati di lavoro si trovano a partire dall’indirizzo 40000. In particolare questo primo indirizzo contiene il risultato dell’intera elaborazione (1 se verifica OK, 0 se corrispondenza non trovata).
In assembly un “valore ritornato” da una generica subroutine è tipicamente un flag settato o meno. In questo caso torna comodo usare il flag zero, stabiliamo che al ritorno da una subroutine il flag Z settato significa “true”.
La versione asm naturalmente è molto più “divertente” in tutti i sensi. Non esistono le variabili, per cui vanno “costruite a mano”, dichiarando esplicitamente delle etichette che rappresentano gli indirizzi di memoria di parole a 16 bit (le nostre variabili puntatore). Per non confondere i nomi delle variabili con quelli dei registri, scriviamo le variabili tra trattini di underscore:
_A_ #DW 0 ;puntatore inizio submask
Lo Z80 ha veramente pochi registri generali (e il set alternativo è scomodo da usare), pertanto è impossibile usare solo i registri per tutte le operazioni.
Il codice qui sopra è una traduzione quasi uno a uno della versione in linguaggio C per Arduino. Alcuni punti (come la subroutine estrazione submask, o la strlen) sono stati pensati direttamente in assembly. Il codice anche se non ottimizzato al massimo, dovrebbe comunque essere più ottimizzato di quello prodotto in automatico da un compilatore.
Di seguito una sessione di test:
$ pyzasm z80_wildcard.asm Z80 Assembler 2.91 - by C.Fin Assemblaggio terminato correttamente Codice prodotto: 363 byte $ zload z80_wildcard.hex Done $ zdump 40000 128 h ----------------------------------------------------------------------- 9C40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9C50: 00 00 00 3F 3F 3F 3F 3F 2A 68 00 31 32 33 34 68 ⬥⬥⬥?????*h⬥1234h 9C60: 68 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 h⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9C70: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9C80: 3F 3F 3F 3F 3F 23 26 23 68 23 55 23 00 00 00 00 ?????#&#h#U#⬥⬥⬥⬥ 9C90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9CA0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9CB0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ $ zcall 32768 $ zdump 40000 128 h ----------------------------------------------------------------------- 9C40: 01 59 9C 59 9C 61 9C 53 9C 5B 9C 59 9C 60 9C 59 ⬥Y⬥Y⬥a⬥S⬥[⬥Y⬥`⬥Y 9C50: 9C 60 9C 3F 3F 3F 3F 3F 2A 68 00 31 32 33 34 68 ⬥`⬥?????*h⬥1234h 9C60: 68 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 h⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9C70: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9C80: 3F 3F 3F 3F 3F 23 26 23 68 23 55 23 00 00 00 00 ?????#&#h#U#⬥⬥⬥⬥ 9C90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9CA0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥ 9CB0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥⬥
La parte di memoria in cui si vedono i caratteri #&#h#U# è solo memoria sporca da precedenti debug (ci ci è voluta un’intera serata per trovare due sciocchi errori nel codice, e correggerne uno nell’assemblatore). I byte della maschera e della stringa sono quelli evidenziati in azzurro e in viola, si tratta di normali stringhe ASCII null-terminated. Dopo l’esecuzione con zcall 32768, il byte rosso impostato a uno all’indirizzo 40000 (0x9C40) è il risultato true prodotto dalla funzione ‘verifica’. Tutti gli altri valori tra il risultato e l’inizio della maschera sono i valori finali delle nove variabili puntatore usate nel programma. In particolare si nota che (in accordo con l’algoritmo) le variabili _A_ e _B_ hanno raggiunto il valore finale 0x9C59 (byte order little endian), che è l’indirizzo fisico dell’ultimo byte della maschera (0x68).
(7/2018)